Intro to Keyword Generator#
Motivation#
While uploading dataset to Depositar, find wikidata keyword for a dataset can be trivious and tedious.
In the current Depositar website, users have to fill in wikidata keyword by their own:
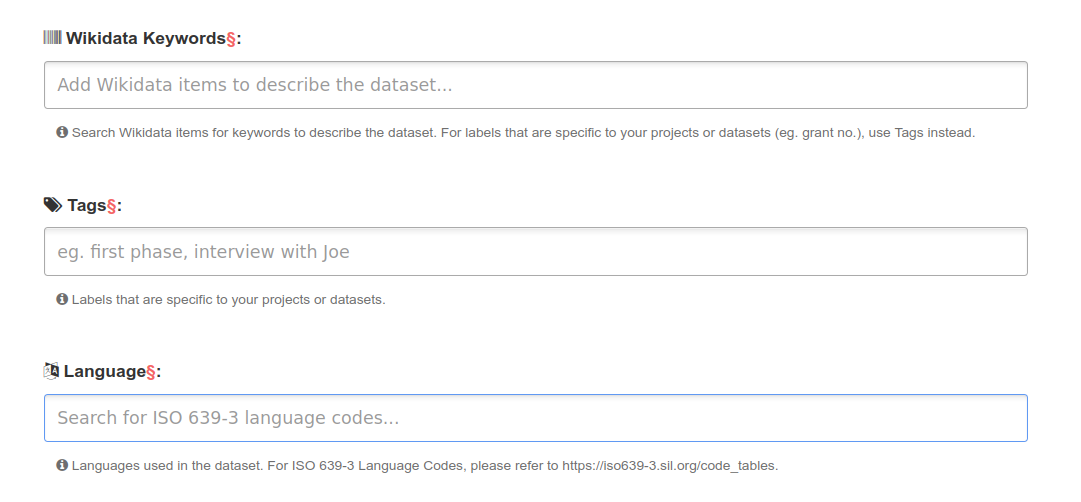
Fig. 1 A screenshot of the Depositar interface for inputting Wikidata keywords#
Thus, we aims to develop a metadata generator, to help users find the apporporiate wikidata keywords to describe their dataset.
Method#
In this seciton, we provide a 2-step pipeline to achieve the goal:
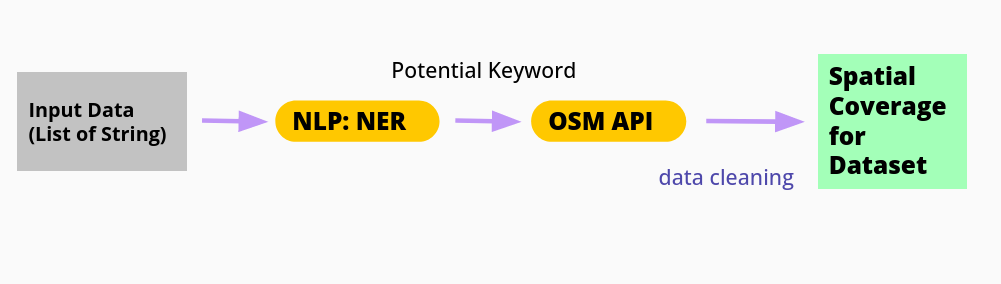
Fig. 2 A pipeline for the keyword generator project#
Stpe 1: NER#
After obtaining the input metadata for the current dataset, we will utilize Named Entity Recognition (NER) on the input data to selectively extract words that could potentially correspond to Wikidata Q-items.
To achieve this goal, we will utilize the ckiplab/bert-base-chinese-ner NLP task model.
The ckiplab/bert-base-chinese-ner model is part of the CKIP Transformers project, which offers transformer models specifically designed for traditional Chinese language processing.
We have selected the ckiplab/bert-base-chinese-ner model due to its superior F1 score in NER when compared to other models provided by CKIP Lab.
Step 2: Wikidata API Search#
Here, we send a search request through the Wikidata API. By using action=wbsearchentities, we can search the Wikidata database using labels and aliases, thus finding the corresponding items that match our input potential keyword.
For more information, check for Media Wiki help: action=wbsearchentities