Exploration and Failed Trials#
During the evolution of this project, we encountered various challenges and sought to implement our project vision in a strategic manner. Here, we outline the issues we encountered, along with the solutions we devised. While certain problems persist without resolution, it’s important to acknowledge our progress thus far.
Furthermore, in the concluding segment, we will delve into our future plans and avenues for enhancing our existing work.
📌 Solved Probelms#
Model file of Ckiptagger need too much spaces#
Problem description: Initially, we opted for the ckiptagger to execute the NLP task. However, this choice necessitated downloading the model files to our local environment prior to usage. Regrettably, the file size is too large to push to GitHub.
Solution: Use ckip-transformers instead. Unlike our previous approach, ckip-transformers doesn’t mandate downloading the model to our local environment; we are able to directly access the model from HuggingFace’s transformers library.
Overpass API Not Returning Coordinates in Counter Clockwise Order#
Problem description: Initially, our intention was to retrieve geographical data using the Overpass API. However, the coordinates returned from this source did not conform to the counter clockwise order.
For instance, provided below is a visual representation of the coordinates obtained from the Overpass API when querying for “南港區” (Nangang District):
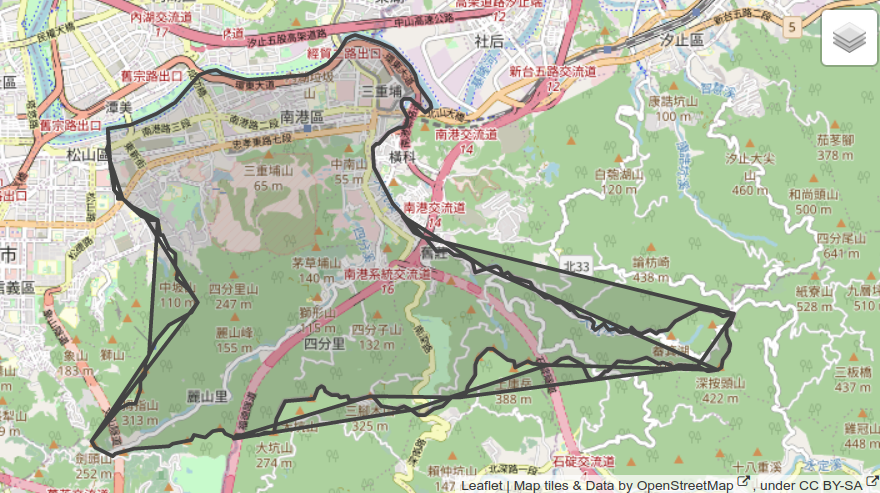
Fig. 4 Boundary of Nangang District as provided by the Overpass API#
Solution: Move to Nominatim API.
Other Solution: Request Overpass API a xml file, and use osmtogeojson to transfer it to geoJSON. No sure why it works.
Cannot Load Data from the Current Repository#
1. Non-image data uploaded does not appear on the site#
Problem description: We have a data file that will be used in our
.ipynb, everything work smoothly in the loacl, but it turns out that the file doesn’t seem to exist when executed remotely.We gueseed this issue arose due to the fact that when we utilized the
jupyterbook --build book_name/command, the script did not transfer additional files or directories to thegh-pagesbranch, which functions as the host for our book’s site. Consequently, the data file remained in our originalmainbranch and became inaccessible via its file path, as it was absent in the site branch.Solution: Move copy the file under
_build/html, and doing this by putting it under thejupyterbook --build book_name/command in makefile. (Notice: in the _deploy.yml, the command we build the whole site ismake, instead of the default,jupyterbook --build book_name/)Other Solutions: An easy way to specify a list of assets that should be copied over. #790
2. Relative path may not work#
Problem description: Even after including the data file in our site branch, we encountered a situation where accessing the file remained problematic. This issue arose from the realization that the file path on the remote server might not align with our initial expectations. Consequently, attempts to use a relative path for loading the file proved to be unsuccessful.
Solution: Use absolute path(url). However, we’ve not found a solution that allows a relative file path.
📌 Unsolved Probelms#
Ipywidget#
Problem description: We found that the Ipywidget widget did not respond as expected to our actions. Despite our attempt to implement the button example provided in the documentation, no visible outcome ensued upon clicking the button. In theory, it should display “Button clicked.” on the screen.
The related topic remains open: widgets not rendering on jupyter-book website (seemingly broken) #1991
Excessive Book Launching Time#
Problem description: Using the
Live Codefeature to run the book within myBinder might result in a prolonged execution time.
📌 Futher Expectation#
Support English Dataset#
As of now, the NER model we are utilizing exclusively supports traditional Chinese, rendering English and other languages incompatible. However, our aspirations involve broadening our language processing capabilities to encompass a wider array of languages in the future.
Sort Search Result by Relevance#
The outcomes from both the Wikidata and OSM API requests adhere to the sequence provided by the respective API responses. Nonetheless, it would greatly enhance user experience if we could arrange these outcomes based on their relevance. This refinement would contribute to a smoother and more user-friendly interface.
Check if Search Result from APIs is Irrelevant to our Dataset#
Occasionally, the search results from Wikidata or OpenStreetMap (OSM) may evidently diverge from our input, and rectifying these inconsistencies remains beyond our control. In such instances, our primary recourse is to devise methods for filtering out undesired outcomes.
Read the Input .pdf or Text Files and Output the Dataset Description#
Our concept revolves around minimizing the metadata input required from users while simultaneously assisting them in augmenting their dataset’s metadata. Moving forward, our next stride could entail extracting textual data from a dataset and autonomously generating a description for it.